JAVA
String / StringBuffer / StringBuilder
string 은 불변하고 Stringbuffer Stringbuilder 은 가변적이다.
- String은 문자열 연산이 적고 자주 참조하는 경우에 좋다. 특히 멀티쓰레드 환경에서는 신경쓸 필요가 없다.
- StringBuffer는 멀티쓰레드환경에서 동기화가 가능하다.
- StringBuilder 는 동기화를 지원하지 않기 떄문에 멀티쓰레드 환경에서는 적합하지 않다.
JAVA String
java에서 string 생성방식에는 두가지가 있습니다.
new연산자를 이용한 방식- 리터럴을 이용한 방식
두 가지 방식에는 큰 차이점이 있습니다. new를 사용해 String을 생성하면 Heap 영역에 존재하게 되고 리터럴을 이용할 경우 string constant pool이라는 영역에 존재하게 됩니다.
string constant pool 은 Perm(permanent)영역에 존재하는데 Java7기점으로 위치가 변경되었습니다.
public class StringMemory {
public static void main(String... args) {
String literal = "loper";
String object = new String("loper");
String intern = object.intern();
System.out.println(literal == object); //false
System.out.println(literal.equals(object)); //true
System.out.println(literal == intern); // true
System.out.println(literal.equals(intern)); // true
}
}String을 리터럴로 선언할 경우 내부적으로 String의 intern()메서드가 호출되게 된다. intern()메서드는 주어진 문자열이 string constant pool에 존재하지는 검색하고 있다면 그 주소값을 반환하고 없다면 string constant pool에 넣고 새로운 주소값을 반환하게 된다.
OOM문제로prem영역에서Heap영역으로 변경되었습니다.Perm영역은 고정된 사이즈고Runtime에 사이즈가 확장되지 않는다. 이동하게 되면서 string constant pool의 모든 문자열도 GC의 대상이 될수 있다는 점이다.
컴파일 과정
java 코드를 javac 컴파일러에 의해 .class 확장자를 가진 바이트코드로 컴파일
클래스로더에 의해 동적으로 컴파일된 바이트코드를 JVM의 메모리에 로드
실행엔진(인터프리터 또는 JIT)에 의해 기계어로 번역되어 실행
Java 메모리 영역
- 메서드(클래스, 스태틱) 영역 : JVM이 읽어들인 클래스, 인터페이스에 대한 런타임 상수 풀, 필드, 스태틱 변수(클래스 변수), 생성자와 메소드를 저장하는 공간
- 런타임 상수 풀 : 클래스와 인터페이스, 상수, 메소드에 대한 모든 레퍼런스 저장. JVM은 런타임 상수 풀에서 메소드나 필드의 실제 메모리상 주소를 찾는다.
- 모든 스레드에서 공유. JVM 시작시 생성되며 프로그램 종료까지 유지됨.
- 힙영역 : new 연산자로 생성된 객체, 배열을 저장하는 공간
- 이 영역에 생성된 객체는 스택 영역의 변수나 다른 객체의 필드에서 참조한다.
- 명시적으로 null, 참조되지 않는 객체는 GC 대상이 됨
- 모든 스레드에서 공유
- 스택영역 : 메소드 정보, 지역변수, 매개변수, 연산 결과를 저장. 각 스레드마다 하나씩 존재. 스레드가 시작될 때 할당
- 메소드가 호출될때마다 프레임이라고 불리는 영역으로 할당됨. 프레임별로 관리되는 것
- primitive 타입은 바로 스택 영역에 저장, 그 외에는 힙 영역이나 메소드 영역의 객체 주소를 저장
힙 영역 자세히
- Young generation : 자바 객체가 생성되자마자 저장
- Eden, Survivor 영역으로 구성
- 시간이 지나 우선순위가 낮아지면 Old 영역으로 이동.
- Minor GC
- Old(Tenured) : young 영역에서 오래된 객체를 이동해 저장하는 영역.
- Major GC(Full GC)
- Permanent : 클래스 로더에 의해 로딩된 클래스, 메소드에 대한 메타정보를 저장하는 영역. JVM에 의해 사용
- 리플렉션을 사용해 동적으로 클래스가 로딩되는 경우 자주 사용

Heap 영역은 크게 Young Generation과 Old Generation으로 나누어져 있습니다.
Young Generation은 Eden 영역과 Survivor 영역으로 구성되는데 Eden 영역은 Object가 Heap 에 최초로 할당되는 장소이며 Eden 영역이 꽉 차게 되면 Object의 참조 여부를 따져 만약 참조가 되어 있는 Live Object이면 Survivor 영역으로 넘기고, 참조가 끊어진 Garbage Object이면 그냥 남겨 놓습니다. 모든 Live Object가 Survivor 영역으로 넘어가면 Eden 영역을 모두 청소합니다. Survivor 영역은 Eden 영역에서 살아남은 Object들이 잠시 머무르는 곳입니다. 이 Survivor영역은 두 개로 구성되는데 하나의 Survivor은 반드시 비어 있는 상태로 남아 있어야합니다. 이러한 과정을 Minor GC라고 합니다.
Young Generation에서 Live Object로 오래 살아남아 성숙된 Object는 Old Generation으로 이동하게 됩니다. 성숙된 Object란 의미는 애플리케이션에서 특정 횟수 이상 참조되어 기준 Age를 초과한 Object를 말합니다. Old Generation 영역은 새로 Heap에 할당되는 Object가 들어오는 것이 아니라, 비교적 오랫동안 참조가 되어 이용되고 앞으로도 계속 사용될 확률이 높은 Object들을 저장하는 영역입니다. 이러한 과정 중 Old Generation의 메모리도 충분하지 않으면 해당 영역에도 GC가 발생하는데 이를 가르켜 Full GC(Major GC)라고 합니다.
자바 동등성과 동일성
- 동일성(identity) 객체가 완전히 같은 객체일 경우 -
hashCode()를 사용하여 판단 - 동등성(equivalent) 객체에 대한 정보가 같을 경우 -
equals()을 사용하여 판단
HashMap, HashSet, HashTable에서는 객체 구분 할때 hashCode()를 사용하여 구분
오버라이딩과 오버로딩 차이
오버라이딩과 오버로딩은 자바의 다형성을 구현하는 대표적인 방법.
오버라이딩은 하위 클래스의 성격에 맞게 부모 클래스의 함수를 재정의 하는 것.
오버로딩은 함수 이름만 같고 파라미터 자료형,개수 등을 다르게 정의으로써 확장된 함수를 새로 정의하고 구현하는 것
컬렉션 프레임워크
다수의 데이터를 쉽고 효과적으로 처리할 수 있는 표준화된 방법을 제공하는 클래스의 집합
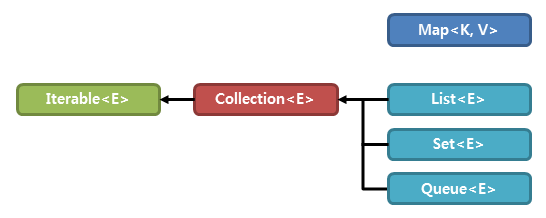

List
- 순서가 있는 데이터의 집합으로 데이터의 중복을 허용함.
Set
- 집합적인 개념의 Collection
- 순서의 의미가 없음
- 데이터를 중복해서 포함할 수 없음.
HashSet : 순서가 필요없는 데이터를 hash table에 저장 (Set 중에 가장 성능이 좋음)
TreeSet : 저장된 데이터의 값에 따라 오름차순 정렬됨.red-black tree 타입으로 저장 (HashSet보다 성능이 느림)
LinkedHashSet : 연결된 목록 타입으로 구현된 hash table에 데이터를 저장. 저장된 순서에 따라 값이 정렬(가장 느림)Map
- List와 Set이 순서나 집합의 개념이라면 Map은 검색의 개념이 추가된 인터페이스
- 데이터 삽입시 Key,Value 형태로 삽입되며 Key를 이용하여 Value를 찾을 수 있음
List 와 Set 인터페이스는 모두 베이스 타입으로 Collection 인터페이스이지만 순서 유무,데이터 중복 여부의 차이가 있습니다.
HashTable vs HashMap
두개 다 map 인터페이스를 구현한 클래스로 중복을 허용하지 않는다.
동기화 시 ConcurrentHashMap도 고려해볼만함.
HashTable : 또한 동기화 처리가 되어 있어 Thread-safe 하다는 특징이 있다. hashMap과는 다르게 key값으로 null을 허용하지 않음.
자바 다중상속을 막은 이유
변수명 충돌이나 중복된 클래스 상속으로 인해 오버라이딩이 모호한 다이아몬드 문제가 있다.
무엇보다 자바는 객체지향언어이기에 다중상속을 지원하면 객체지향이 무너질 수 있다. 객체지향의 단일책임 원칙에 의해 클래스는 오직하나의 기능을 가지고 그 하나의 책임에 집중해야된다.
이런 문제를 Interface와 Composition Pattern을 사용하여 해결할 수 있다.
여러 클래스를 맴버필드에 포함시켜 객체의 기능은 확장시키고 부모 클래스로부터 받은 성격은 유지 할 수 있다.
CS
자료구조 / 알고리즘
ArrayList VS LinkedList
ArrayList
- 내부적으로 배열로 구현되어있고, 삽입 삭제시 O(n)
- 인덱스를 알면 O(1) 로 접근 가능하므로, 임의 접근 가능
- 내용이 꽉차면 배열의 크기를 2배로 늘리고 이동 O(n)
- 논리적, 물리적 저장 순서가 일치
- 캐시 효율도 굳 -> 연관된 데이터가 몰려있을 가능성 up
LinkedList
- 노드간 연결로 구현, 끝부분에서 삽입 삭제시 O(1)
- 원하는 곳에 삽입 삭제 시 O(n) -> 원하는 인덱스를 얻으려면 처음부터 찾아야하므로
- 결국 배열보다 구리지만, Tree 에서 쓸만한 자료구조
Stack, Queue에 대한 간단한 설명
Stack - LIFO
Queue - FIFO
해시 자료구조가 무엇인가?
해시 충돌 해결법
Open Address 방식(개방주소법)
Linear Probing
순차적으로 탐색하여 비어있는 버킷을 찾을 때까지 계속 진행
Quadratic probing
2차 함수를 이용해 탐색할 위치를 찾는다.
Double hashing probing
하나의 해쉬함수에서 충돌이 발생하면 2차 해쉬함수를 이용해 새로운 주소를 할당.
Separate Chaining 방식(분리 연결법)
- 연결리스트를 사용하는 방식(Linked List)
- 트리를 사용하는 방식(Red-Black Tree)
정렬
퀵정렬
배열로 구현한 Heap
- 배열로 구현할 경우 간단한 인덱스 연산으로 부모노드, 자식노드를 구할 수 있기 때문에 간편하다.
시간복잡도
| 삽입 | 삭제 | 최소값(최대값) |
|---|---|---|
| O(logN) | O(logN) | O(1) |
** 삽입연산 **
1. (lastIndex + 1) 위치에 데이터를 삽입한다.
2. upHeap(lastIndex + 1) 함수를 호출한다.
** upHeap 연산 **
- 부모노드가 존재하지 않을 경우 (index가 1인 경우) 함수 종료
1. 부모노드를 구한다. 부모노드 = index / 2
- 부모노드가 현재노드보다 작다면(혹은 크다면) 함수 종료
2. 부모노드와 자식노드의 값을 교환한다.
3. upHeap(부모노드 인덱스) 반복 // 현재 노드가 가장 작다면(혹은 크다면) 루트까지 올라간다.
** 삭제연산(최소값 or 최대값 리턴) **
1. 부모노드의 값을 리턴하고, 맨 마지막 노드를 부모노드로 옮긴다.
2. downHeap(1) 함수를 호출한다.
** downHeap 연산 **
- 만약 단말노드일 경우(현재 index * 2 > 사이즈 - 1) 함수 종료
1. 현재 노드를 기준으로, 왼쪽 자식노드와 오른쪽 자식노드의 인덱스를 구한다.
2. 부모노드와 비교 할 인덱스를 구한다.
- if 오른쪽 인덱스가 힙 사이즈를 벗어날 경우 then 왼쪽 인덱스
- else 왼쪽, 오른쪽 중 작은(혹은 큰) 값을 가진 인덱스
3. 부모노드가 힙 조건을 만족할 경우, 그냥 함수 종료
4. 부모노드와 교환
5. downHeap(교환한 인덱스) 반복OS
임계구역 문제 해결법
교착상태 : 다중 프로그래밍 시스템에서 하나 또는 그 이상의 프로세스가 수행할 수 없는 어떤 특정 이벤트를 기다리는 상태
- 한정된 자원을 사용하려고 서로 경쟁하는 상황
- 프로세스가 자원을 요청시 그 시각에 해당 자원을 누군가가 사용하거나 점유하여 사용할 수 없는 상태가 발생하여 대기 상태가 발생하는 상황
- 대기상태가 다시 실행 상태로 변경되지 않을 경우
교착상태의 특징
- 상호배제(Mutual exclusion) : 한번에 오직 한 프로세스만 자원을 사용
- 점유대기(Hold and wait) : 프로세스가 적어도 하나의 자원을 점유하면서 다른 프로세스가 점유하고 있는 자원을 추가로 얻기위해 대기
- 비선점(No preemption) : 점유된 자원은 강제로 해제될 수 없고, 점유하고 있는 프로세스가 작업을 마치고 자원을 자발적으로 해제
- 순환대기(Circular wait) : 대기하고 있는 프로세스 집합에서 P0 ~ Pn에서 꼬리를 물면서 점유한 자원을 계속 대기하고 있는 상태
처리 방법
- 교착상태 예방:
- 교착상태 필요 조건이 발생하지 않도록 보장
- 교착상태 회피:
- 자원 할당 그래프 알고리즘 이용
- 교착상태 탐지
- 교착상태가 발생한 프로세스들을 알아내는 알고리즘을 통해 교착상태를 탐지하여 외부에서 해결
- 교착상태 회복
- 프로세스 종료 :
- 교착상태가 제거 될 떄까지 한 프로세스 씩 중지.
- 교착상태에 속한 프로세스를 모두 중지
- 자원 선점
- 교착상태가 제거될 때까지 자원을 선점하여 다른 프로세스에게 할당 해주는 방식.
- 프로세스 종료 :
프로세스와 쓰레드
프로세스는 메모리에 올라와 실행 중인 프로그램 인스턴스이고 스레드는 프로세스내에서 실행되는 여러 흐름의 단위 입니다.
멀티 프로세싱- 하나의 응용프로그램을 여러 개의 프로세스로 구성하여 각 프로세스가 하나의 작업을 처리하도록 하는 것
장점: 여러 개의 자식 프로세스 중 하나에 문제가 발생하면 그 자식 프로세스만 죽는 것 이상으로 다른 영향이 확산 되지 않는다.
단점: Context Switching에서의 오버헤드
Context Switching 과정에서 캐쉬 메모리 초기화 등 무거운 작업이 진행되고 많은 시간이 소모되는 등의 오버헤드가 발생.
프로세스 사이의 어렵고 복잡한 통신기법(IPC)
프로세스는 각각 독립된 메모리 영역을 할당받았기 때문에 하나의 프로그램에 속하는 프로세스들 사이의 변수를 공유할 수 없다.
멀티 쓰레딩 - 하나의 응용프로그램을 여러 개의 쓰레드로 구성하고 각 쓰레드로 하여금 하나의 작업을 처리 하도록 하는 것이다.
- 장점 : 시스템 자원 소모 감소
- 시스템 처리량 증가 : 프로세스 간의 통신보다 쓰레드 간 통신이 비용이 적으므로 통신 비용이 줄어들게 된다.
- 단점: 잘못된 변수 공유와 미묘한 시간으로 오류 발생 확률 증가
- 동기화의 문제가 발생한다.
- 하나의 쓰레드에 문제가 발생하면 전체 프로세스가 영향을 받는다.
- 장점 : 시스템 자원 소모 감소
네트워크
TCP UDP 차이
전송계층 프로토콜로 TCP는 연결형이고 높은 신뢰성을 가집니다. 데이터의 흐름제어 및 혼잡제어를 할 수 있습니다. UDP는 비연결형이며 비신뢰성을 가집니다.
흐름제어
송신측과 수신측의 데이터처리 속도 차이를 해결하기 위한 기법
stop and wait 방식
매번 전송한 패킷에 대해 확인 응답을 받아야만 그 다음 패킷을 전송합니다.
슬라이딩 윈도우
여러개의 연속된 패킷을 한번에 전송하고 전송완료된 패킷들에 대해 한번의 확인 응답을 받고 전송된 패킷 수만큼 다음 패킷들을 다시 윈도우에 포함 시켜 전송할 수 있게 합니다.
전송 실패 시 선택 방법
고백 N
송신 측에서 0,1,2,3 패킷을 보냈을 때 2번 패킷에서 전송 오류가 나면 2번에 대한 부정응답을 보내고 2번 뒤로 받은 패킷을 모두 버리고 다시 받음.
선택적 재전송
받지 못한 패킷에 대해서만 부정응답을 보내 받음.
혼잡 제어
송신측의 데이터 전달과 네트워크의 데이터 처리속도 차이를 해결하기 위한 기법
AIMD (Additive Increase / Multicative Decrease)
처음에 패킷을 하나씩 보내고 이것이 문제없이 도착하면 window크기(단위 시간 내에 보내는 패킷의 수)를 1씩 증가시켜가며 전송하는 방법입니다. 만일 패킷전송을 실패하거나 일정 시간을 넘으면 패킷을 보내는 속도를 절반으로 줄이게 됩니다.
Slow start
미리 정해진 임계 값에 도달할 때까지 윈도우의 크기를 2배씩 증가
윈도우의 크기가 임계 값에 도달 한 이후 혼잡회피단계로 넘어가 전송한 데이터에 대한 ACK를 받으면 윈도우 크기를 1개씩 증가
빠른 재전송(Fast Retransmit)
응답되는 ack가 중복된 값이면 패킷 손실로 판단하고 타임아웃시간을 대기하지 않고 즉시 해당 패킷을 재전송 요청한다.
SIngleton 패턴
전역 변수를 사용하지 않고 객체를 하나만 생성하고 생성된 객체를 어디서든지 참조할 수 있도록 하는 패턴
쓰는 이유
커넥션 풀이나 환경 설정 클래스같이 인스턴스를 두개 이상 만들면 race condition이 발생하거나,
리소스를 불필요하게 더 필요로 한 상황을 제거하기위해.
전역 인스턴스여서 다른 클래스 인스턴스가 데이터를 공유하기 쉬움.
전역변수로 하면 되지 않나?
- 전역 변수를 통해 객체 생성을 하면 싱글턴 패턴과 마찬가지로 작동은 하나 만약 객체가 자원을 많이 차지함에도 불구하고 실행동안 한번도 사용되지 않는다면 자원 낭비가 있을 수 있기 때문에 호출시 생성되도록 만드는 것이 좋다.
'면접질문들' 카테고리의 다른 글
| Java8 변경 사항 (0) | 2019.03.26 |
|---|---|
| 프로세스와 쓰레드의 차이 (1) | 2019.03.25 |